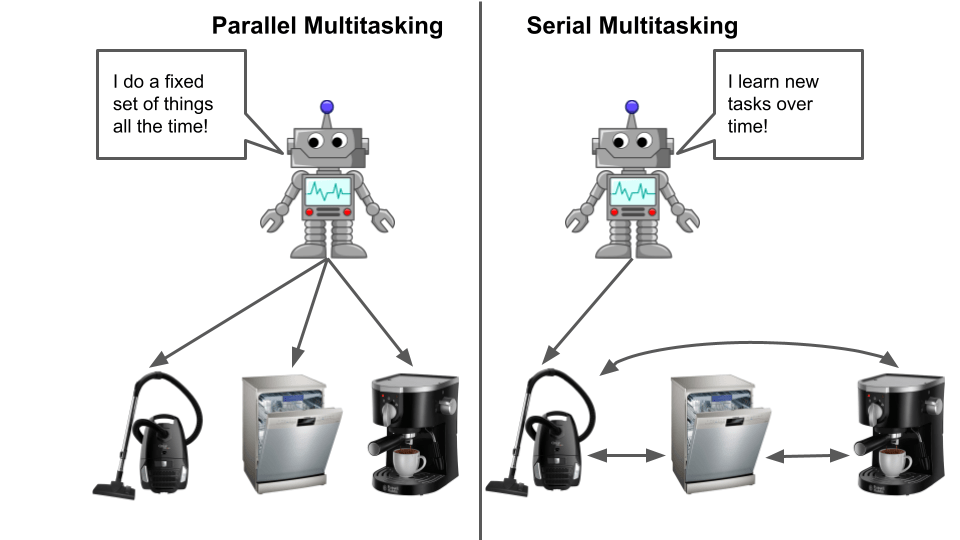
While a great deal of focus in modern machine learning is on improving performance on well-defined single tasks such as Imagenet classification, even the simplest animal must learn to perform multiple “tasks.” While some machine learning tasks can be learned and applied in isolation, most of the applications we imagine using reinforcement learning for (robotic manipulation, playing video games, conversing with humans, etc) inherently require some degree of multitasking. The fact that multitask RL is currently not very good is thus problematic.
Category Archives: reinforcement learning
Why is Reinforcement Learning Hard: Generalization

Anyone who is passingly familiar with reinforcement learning knows that getting an RL agent to work for a task, whether a research benchmark or a real-world application, is difficult. Further, there’s no one reason for this, and the causes span both the practical and theoretical. In this post, I’m gonna go into detail on one such obstacle: generalization.
Detecting Bottlenecks in Deep RL, Part 2: Sampling
This blog post is about methods for detecting bottlenecks in RL agents, a topic which (to my knowledge) hasn’t been explicitly described anywhere before. The goal is to define metrics of an agent’s performance which can be used by a human researcher to diagnose which factors are performance-limiting so they can be improved upon via various methods. In essence, how do we identify the practical limitations of our algorithms?
Detecting Bottlenecks in Deep Reinforcement Learning, Part 1

Today I’m starting a series of posts on learning bottlenecks in deep reinforcement learning. In this post I’ll describe the problem and some examples of how it expresses itself, with follow-on posts that go into more details on bottlenecks in specific aspects of an RL agent and how they can be resolved.
