
Hi, I’m Riley Simmons-Edler, a PhD Student at Princeton University studying reinforcement learning. I’ve also interned at Samsung AI Center NYC working on robotic RL, and in a past life I worked on computational protein modeling in my undergrad at NYU.
Contact me at: rileys AT cs DOT princeton DOT edu
Or find me online:
My Research Interests
- Reinforcement Learning
- Robotics
- AI Creativity
- Program Synthesis
- Bio-Inspired AI
- Applied RL
Places I’ve worked
PhD Student, Computer Science Department, Princeton University
(2015 – 2021)
As a PhD student I’ve worked on a few different topics, most notably my thesis on sampling methods for deep reinforcement learning, supervised by Prof. Sebastian Seung. I’ve also worked on some side projects in computer graphics, neural network architectures, NLP, program synthesis, and ultrasonic sensing. I’ve TA’d classes on computer graphics, vision, and neural network fundamentals.
Research Intern, Samsung AI Center NYC
(2018 – 2021)
The last two and a half years I was an intern at the Samsung AI Center in New York, where I worked under Professor/EVP Daniel Lee on reinforcement learning for continuous control and robotics. I also did some work using neural networks for acoustic sensing as a side project.
Research Assistant, Bonneau Lab, NYU
(2011 – 2014)
In my previous life as an undergraduate, I worked with Prof. Rich Bonneau at NYU on the simulation and modeling of folded protein structures for protein design.
Blog Posts

Why is Reinforcement Learning Hard: Multitask Learning
While a great deal of focus in modern machine learning is on improving performance on well-defined single tasks such as Imagenet classification, even the simplest animal must learn to perform multiple “tasks.” While some machine learning tasks can be learned and applied in isolation, most of the applications we imagine using reinforcement learning for (robotic…
Keep reading
Why is Reinforcement Learning Hard: Generalization
Anyone who is passingly familiar with reinforcement learning knows that getting an RL agent to work for a task, whether a research benchmark or a real-world application, is difficult. Further, there’s no one reason for this, and the causes span both the practical and theoretical. In this post, I’m gonna go into detail on one…
Keep readingDetecting Bottlenecks in Deep RL, Part 2: Sampling
This blog post is about methods for detecting bottlenecks in RL agents, a topic which (to my knowledge) hasn’t been explicitly described anywhere before. The goal is to define metrics of an agent’s performance which can be used by a human researcher to diagnose which factors are performance-limiting so they can be improved upon via…
Keep readingMy Recent Papers
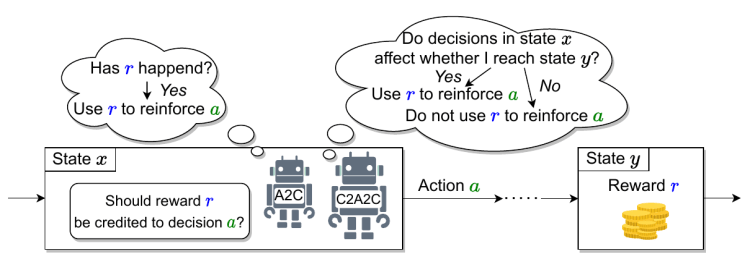
Towards Practical Credit Assignment for Deep Reinforcement Learning
Vyacheslav Alipov, Riley Simmons-Edler, Nikita Putintsev, Pavel Kalinin, Dmitry Vetrov
Credit assignment, the process of deciding which past actions affect future rewards in reinforcement learning, is a key part of any RL task, but methods to do this explicitly to speed up the learning process have been largely theoretical and confined to tabular RL tasks until now.
In this paper, we explored some of the challenges involved in explicit credit assignment for deep RL, and developed a new credit assignment algorithm that speeds up training on a subset of Atari games, suggesting a way forward for practical credit assignment.
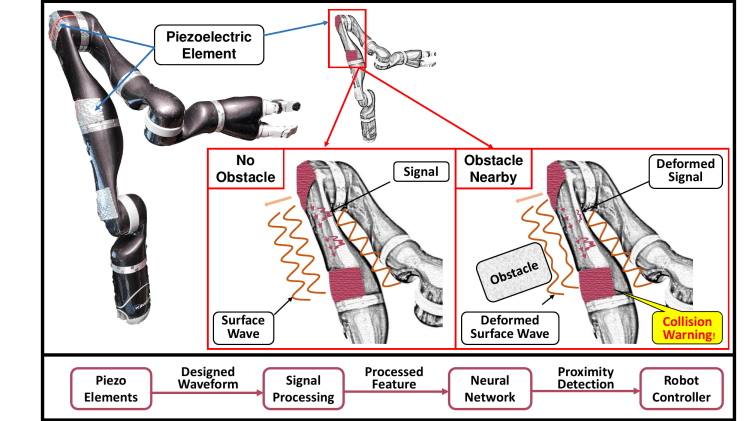
AuraSense: Robot Collision Avoidance by Full-Surface Proximity Detection
Xiaoran Fan, Riley Simmons-Edler, Daewon Lee, Larry Jackel, Richard Howard, Daniel Lee
In this paper, we explored a new method for ultrasonic proximity detection using what we termed the Leaky Surface Wave (LSW) effect. The LSW allows us to emit and receive ultrasonic waves across the whole surface of an object, and thus detect proximity anywhere around it (not just in front of the sensor as in a traditional ultrasonic proximity sensor), but complicates signal processing due to multipath effects.
To counteract this, we used a neural network model to predict proximity (in this case a binary label) from the received signal, and achieve >90% accuracy at proximity detection for diverse objects on a moving robot platform (and >99% on a stationary robot). Our method is simple and cheap to implement and run, while providing full-surface proximity detection for an off-the-shelf robot with minimal modifications.
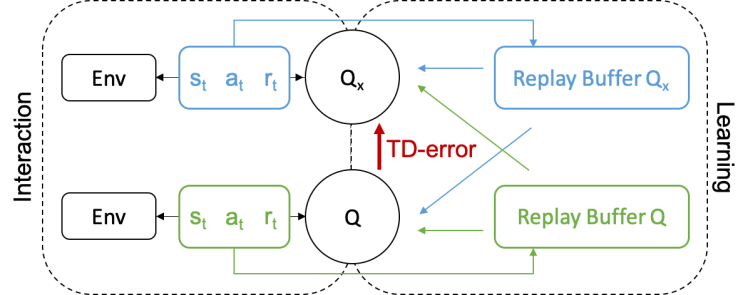
Reward Prediction Error as an Exploration Objective in Deep Reinforcement Learning
Riley Simmons-Edler, Ben Eisner, Daniel Yang, Anthony Bisulco, Eric Mitchell, Sebastian Seung, Daniel Lee
In order for RL agents to learn, they need to explore their environment to find sources of improved reward. Methods for encouraging an agent to try new things (or indeed, what “new” means here) are diverse and often depend on the special structure of the task.
In this paper, we propose a new exploration objective, reward prediction error (how mistaken the agent is about future rewards), which applies to many types of tasks, where previous objectives might only be suitable for a subset of tasks. Using RPE we develop an algorithm, QXplore, which can solve several types of hard exploration problems, where previous algorithms could only solve a subset of them.
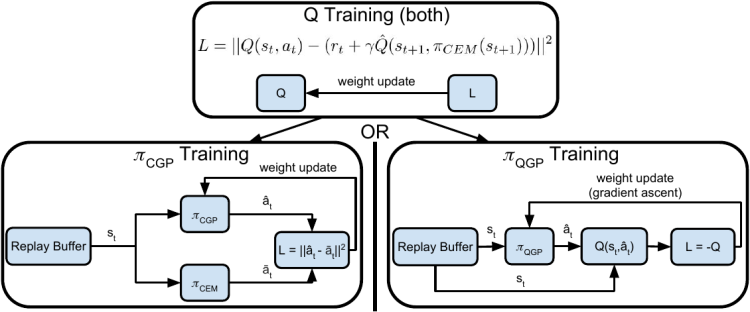
Q-Learning for Continuous Actions with Cross-Entropy Guided Policies
Riley Simmons-Edler*, Ben Eisner*, Eric Mitchell*, Sebastian Seung, Daniel Lee
* = Equal Contribution
A major challenge in Q-learning is how to select an optimal action with respect to Q(s,a) when a is continuous-valued. Using a sample-based optimizer to select actions is stable and performant, but slow to compute and thus not well suited for real-time tasks, such as in robotics.
In this work, we developed an algorithm that obtains the best of both worlds: we use a sample-based optimizer when training (where compute time is less critical), and train a neural network to imitate the sample-based optimizer for use at test time (when speed and compute costs are more important). We show that this approach performs similarly to the sample-based optimizer, and retains its stability benefits, but runs much faster at test time, making it well-suited for real-time RL applications.
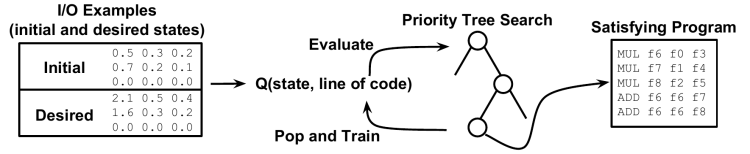
Program Synthesis Through Reinforcement Learning Guided Tree Search
Riley Simmons-Edler, Anders Miltner, Sebastian Seung
Program synthesis, the automatic generation of computer programs that meet some specification, is a problem as old as computer science, but has proven difficult due to huge search space and the sparsity of satisfying programs in that space. Much research on this task has focused on search algorithms with heuristics to reduce the size of the search space, which are usually domain-specific and impose significant constraints on possible programs.
We propose instead a hybrid RL+search approach, RL Guided Tree Search (RLGTS), which uses a Q-function to evaluate the expected reward (how close the program is to satisfying the specification) for unexplored edges in the program tree, and then explores using priority tree search among the Q-evaluated edges. This approach effectively learns heuristics about the program domain which must otherwise be encoded by a language expert, and is domain-agnostic. We demonstrate RLGTS on a subset of RISC-V assembly, where no good heuristics are known to exist, and find that it dramatically outperforms a stochastic MCMC baseline algorithm in sample efficiency.
